 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Visual Odometry
Monocular visual odometry is the process of estimating the motion of a camera using a single camera and visual features.
Papers and Code
Vision-only UAV State Estimation for Fast Flights Without External Localization Systems: A2RL Drone Racing Finalist Approach
Feb 02, 2026Fast flights with aggressive maneuvers in cluttered GNSS-denied environments require fast, reliable, and accurate UAV state estimation. In this paper, we present an approach for onboard state estimation of a high-speed UAV using a monocular RGB camera and an IMU. Our approach fuses data from Visual-Inertial Odometry (VIO), an onboard landmark-based camera measurement system, and an IMU to produce an accurate state estimate. Using onboard measurement data, we estimate and compensate for VIO drift through a novel mathematical drift model. State-of-the-art approaches often rely on more complex hardware (e.g., stereo cameras or rangefinders) and use uncorrected drifting VIO velocities, orientation, and angular rates, leading to errors during fast maneuvers. In contrast, our method corrects all VIO states (position, orientation, linear and angular velocity), resulting in accurate state estimation even during rapid and dynamic motion. Our approach was thoroughly validated through 1600 simulations and numerous real-world experiments. Furthermore, we applied the proposed method in the A2RL Drone Racing Challenge 2025, where our team advanced to the final four out of 210 teams and earned a medal.
360DVO: Deep Visual Odometry for Monocular 360-Degree Camera
Jan 05, 2026Monocular omnidirectional visual odometry (OVO) systems leverage 360-degree cameras to overcome field-of-view limitations of perspective VO systems. However, existing methods, reliant on handcrafted features or photometric objectives, often lack robustness in challenging scenarios, such as aggressive motion and varying illumination. To address this, we present 360DVO, the first deep learning-based OVO framework. Our approach introduces a distortion-aware spherical feature extractor (DAS-Feat) that adaptively learns distortion-resistant features from 360-degree images. These sparse feature patches are then used to establish constraints for effective pose estimation within a novel omnidirectional differentiable bundle adjustment (ODBA) module. To facilitate evaluation in realistic settings, we also contribute a new real-world OVO benchmark. Extensive experiments on this benchmark and public synthetic datasets (TartanAir V2 and 360VO) demonstrate that 360DVO surpasses state-of-the-art baselines (including 360VO and OpenVSLAM), improving robustness by 50% and accuracy by 37.5%. Homepage: https://chris1004336379.github.io/360DVO-homepage
Drift-Corrected Monocular VIO and Perception-Aware Planning for Autonomous Drone Racing
Dec 23, 2025



The Abu Dhabi Autonomous Racing League(A2RL) x Drone Champions League competition(DCL) requires teams to perform high-speed autonomous drone racing using only a single camera and a low-quality inertial measurement unit -- a minimal sensor set that mirrors expert human drone racing pilots. This sensor limitation makes the system susceptible to drift from Visual-Inertial Odometry (VIO), particularly during long and fast flights with aggressive maneuvers. This paper presents the system developed for the championship, which achieved a competitive performance. Our approach corrected VIO drift by fusing its output with global position measurements derived from a YOLO-based gate detector using a Kalman filter. A perception-aware planner generated trajectories that balance speed with the need to keep gates visible for the perception system. The system demonstrated high performance, securing podium finishes across multiple categories: third place in the AI Grand Challenge with top speed of 43.2 km/h, second place in the AI Drag Race with over 59 km/h, and second place in the AI Multi-Drone Race. We detail the complete architecture and present a performance analysis based on experimental data from the competition, contributing our insights on building a successful system for monocular vision-based autonomous drone flight.
Aerial Vision-Language Navigation with a Unified Framework for Spatial, Temporal and Embodied Reasoning
Dec 09, 2025Aerial Vision-and-Language Navigation (VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and navigate complex urban environments using onboard visual observation. This task holds promise for real-world applications such as low-altitude inspection, search-and-rescue, and autonomous aerial delivery. Existing methods often rely on panoramic images, depth inputs, or odometry to support spatial reasoning and action planning. These requirements increase system cost and integration complexity, thus hindering practical deployment for lightweight UAVs. We present a unified aerial VLN framework that operates solely on egocentric monocular RGB observations and natural language instructions. The model formulates navigation as a next-token prediction problem, jointly optimizing spatial perception, trajectory reasoning, and action prediction through prompt-guided multi-task learning. Moreover, we propose a keyframe selection strategy to reduce visual redundancy by retaining semantically informative frames, along with an action merging and label reweighting mechanism that mitigates long-tailed supervision imbalance and facilitates stable multi-task co-training. Extensive experiments on the Aerial VLN benchmark validate the effectiveness of our method. Under the challenging monocular RGB-only setting, our model achieves strong results across both seen and unseen environments. It significantly outperforms existing RGB-only baselines and narrows the performance gap with state-of-the-art panoramic RGB-D counterparts. Comprehensive ablation studies further demonstrate the contribution of our task design and architectural choices.
DualVision ArthroNav: Investigating Opportunities to Enhance Localization and Reconstruction in Image-based Arthroscopy Navigation via External Cameras
Nov 12, 2025


Arthroscopic procedures can greatly benefit from navigation systems that enhance spatial awareness, depth perception, and field of view. However, existing optical tracking solutions impose strict workspace constraints and disrupt surgical workflow. Vision-based alternatives, though less invasive, often rely solely on the monocular arthroscope camera, making them prone to drift, scale ambiguity, and sensitivity to rapid motion or occlusion. We propose DualVision ArthroNav, a multi-camera arthroscopy navigation system that integrates an external camera rigidly mounted on the arthroscope. The external camera provides stable visual odometry and absolute localization, while the monocular arthroscope video enables dense scene reconstruction. By combining these complementary views, our system resolves the scale ambiguity and long-term drift inherent in monocular SLAM and ensures robust relocalization. Experiments demonstrate that our system effectively compensates for calibration errors, achieving an average absolute trajectory error of 1.09 mm. The reconstructed scenes reach an average target registration error of 2.16 mm, with high visual fidelity (SSIM = 0.69, PSNR = 22.19). These results indicate that our system provides a practical and cost-efficient solution for arthroscopic navigation, bridging the gap between optical tracking and purely vision-based systems, and paving the way toward clinically deployable, fully vision-based arthroscopic guidance.
BEV-ODOM2: Enhanced BEV-based Monocular Visual Odometry with PV-BEV Fusion and Dense Flow Supervision for Ground Robots
Sep 18, 2025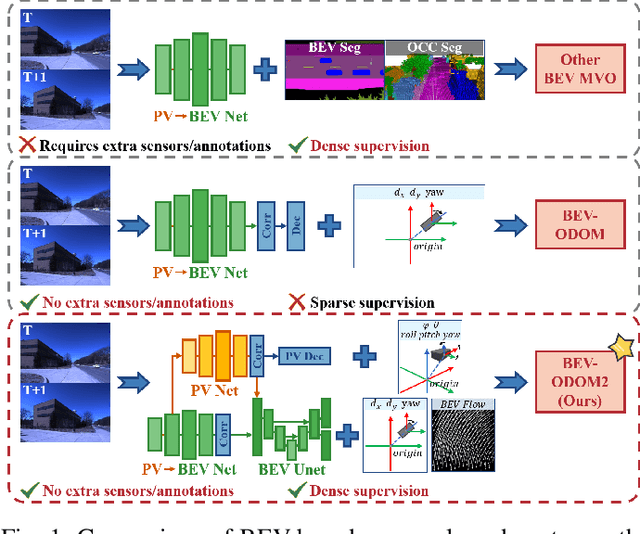
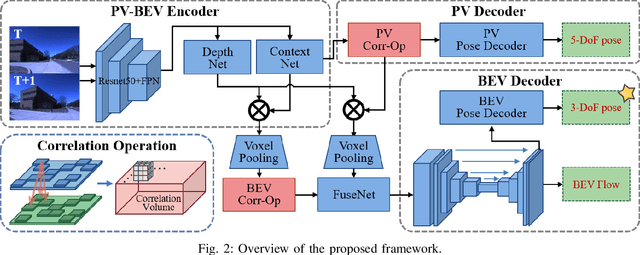
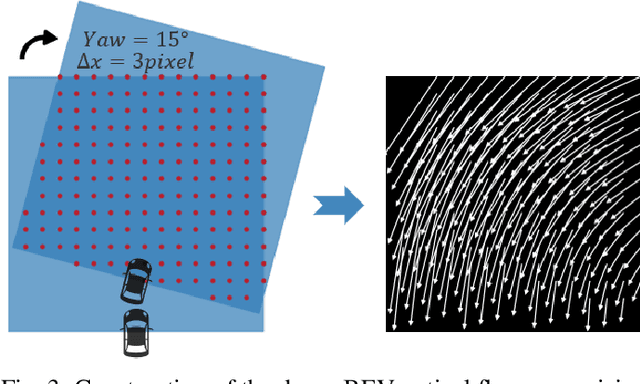
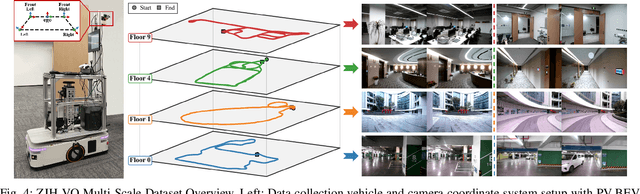
Bird's-Eye-View (BEV) representation offers a metric-scaled planar workspace, facilitating the simplification of 6-DoF ego-motion to a more robust 3-DoF model for monocular visual odometry (MVO) in intelligent transportation systems. However, existing BEV methods suffer from sparse supervision signals and information loss during perspective-to-BEV projection. We present BEV-ODOM2, an enhanced framework addressing both limitations without additional annotations. Our approach introduces: (1) dense BEV optical flow supervision constructed from 3-DoF pose ground truth for pixel-level guidance; (2) PV-BEV fusion that computes correlation volumes before projection to preserve 6-DoF motion cues while maintaining scale consistency. The framework employs three supervision levels derived solely from pose data: dense BEV flow, 5-DoF for the PV branch, and final 3-DoF output. Enhanced rotation sampling further balances diverse motion patterns in training. Extensive evaluation on KITTI, NCLT, Oxford, and our newly collected ZJH-VO multi-scale dataset demonstrates state-of-the-art performance, achieving 40 improvement in RTE compared to previous BEV methods. The ZJH-VO dataset, covering diverse ground vehicle scenarios from underground parking to outdoor plazas, is publicly available to facilitate future research.
Observer Design for Optical Flow-Based Visual-Inertial Odometry with Almost-Global Convergence
Aug 28, 2025This paper presents a novel cascaded observer architecture that combines optical flow and IMU measurements to perform continuous monocular visual-inertial odometry (VIO). The proposed solution estimates body-frame velocity and gravity direction simultaneously by fusing velocity direction information from optical flow measurements with gyro and accelerometer data. This fusion is achieved using a globally exponentially stable Riccati observer, which operates under persistently exciting translational motion conditions. The estimated gravity direction in the body frame is then employed, along with an optional magnetometer measurement, to design a complementary observer on $\mathbf{SO}(3)$ for attitude estimation. The resulting interconnected observer architecture is shown to be almost globally asymptotically stable. To extract the velocity direction from sparse optical flow data, a gradient descent algorithm is developed to solve a constrained minimization problem on the unit sphere. The effectiveness of the proposed algorithms is validated through simulation results.
DINO-VO: A Feature-based Visual Odometry Leveraging a Visual Foundation Model
Jul 17, 2025Learning-based monocular visual odometry (VO) poses robustness, generalization, and efficiency challenges in robotics. Recent advances in visual foundation models, such as DINOv2, have improved robustness and generalization in various vision tasks, yet their integration in VO remains limited due to coarse feature granularity. In this paper, we present DINO-VO, a feature-based VO system leveraging DINOv2 visual foundation model for its sparse feature matching. To address the integration challenge, we propose a salient keypoints detector tailored to DINOv2's coarse features. Furthermore, we complement DINOv2's robust-semantic features with fine-grained geometric features, resulting in more localizable representations. Finally, a transformer-based matcher and differentiable pose estimation layer enable precise camera motion estimation by learning good matches. Against prior detector-descriptor networks like SuperPoint, DINO-VO demonstrates greater robustness in challenging environments. Furthermore, we show superior accuracy and generalization of the proposed feature descriptors against standalone DINOv2 coarse features. DINO-VO outperforms prior frame-to-frame VO methods on the TartanAir and KITTI datasets and is competitive on EuRoC dataset, while running efficiently at 72 FPS with less than 1GB of memory usage on a single GPU. Moreover, it performs competitively against Visual SLAM systems on outdoor driving scenarios, showcasing its generalization capabilities.
UNO: Unified Self-Supervised Monocular Odometry for Platform-Agnostic Deployment
Jun 08, 2025This work presents UNO, a unified monocular visual odometry framework that enables robust and adaptable pose estimation across diverse environments, platforms, and motion patterns. Unlike traditional methods that rely on deployment-specific tuning or predefined motion priors, our approach generalizes effectively across a wide range of real-world scenarios, including autonomous vehicles, aerial drones, mobile robots, and handheld devices. To this end, we introduce a Mixture-of-Experts strategy for local state estimation, with several specialized decoders that each handle a distinct class of ego-motion patterns. Moreover, we introduce a fully differentiable Gumbel-Softmax module that constructs a robust inter-frame correlation graph, selects the optimal expert decoder, and prunes erroneous estimates. These cues are then fed into a unified back-end that combines pre-trained, scale-independent depth priors with a lightweight bundling adjustment to enforce geometric consistency. We extensively evaluate our method on three major benchmark datasets: KITTI (outdoor/autonomous driving), EuRoC-MAV (indoor/aerial drones), and TUM-RGBD (indoor/handheld), demonstrating state-of-the-art performance.
A Novel ViDAR Device With Visual Inertial Encoder Odometry and Reinforcement Learning-Based Active SLAM Method
Jun 16, 2025In the field of multi-sensor fusion for simultaneous localization and mapping (SLAM), monocular cameras and IMUs are widely used to build simple and effective visual-inertial systems. However, limited research has explored the integration of motor-encoder devices to enhance SLAM performance. By incorporating such devices, it is possible to significantly improve active capability and field of view (FOV) with minimal additional cost and structural complexity. This paper proposes a novel visual-inertial-encoder tightly coupled odometry (VIEO) based on a ViDAR (Video Detection and Ranging) device. A ViDAR calibration method is introduced to ensure accurate initialization for VIEO. In addition, a platform motion decoupled active SLAM method based on deep reinforcement learning (DRL) is proposed. Experimental data demonstrate that the proposed ViDAR and the VIEO algorithm significantly increase cross-frame co-visibility relationships compared to its corresponding visual-inertial odometry (VIO) algorithm, improving state estimation accuracy. Additionally, the DRL-based active SLAM algorithm, with the ability to decouple from platform motion, can increase the diversity weight of the feature points and further enhance the VIEO algorithm's performance. The proposed methodology sheds fresh insights into both the updated platform design and decoupled approach of active SLAM systems in complex environments.
* 12 pages, 13 figures